
This post is created with one specific objective: “Know the principal tools and techniques for creating analytical projects with ETL process”. But what is ETL? The concepts are basic and don´t need deep knowledge. The first step to understand is remember the Data Analytics lifecycle:
Discovery, the team learns the business domain, including relevant history such as whether the organization or business unit has attempted similar projects in the past from which they can learn. The team assesses the resources available to support the projects in terms of people, technology, time and data.
Data Preparation, in this phase requires the presence of an analytic sandbox, in which the team can work with data and perform analytics for the duration of the project. The team needs to execute extract, load, and transform (ETL) to get data into the sandbox. Yes! This is the point to analyze.
Model Planning, phase 3 where the team determines the methods, techniques, and workflow it intends to follow for the subsequent model building phase. The team explores the data to learn about the relationship between variables and subsequently selects key variables and the most suitable models.
Model Building, the team develops datasets for testing, training and production purposes. Also, the team executes models based on the work done in the model planning phase.
Communicate Results, in collaboration with major stakeholders, determines if the results of the project are success or a failure based on the criteria developed in phase 1 Discovery.
Operationalize, the team delivers final reports, briefings, code and technical documents. In addition, the team runs a pilot project to implement the models in production environment.
Alright, it’s time to understand phase 2 in depth: Data Preparation. This phase consumes 80% of all time of the Data Analytics lifecycle. The key activities are:
- Establish the analytic sandbox
- ETL (sometimes ELTL)
- Data exploration
- Data conditioning
- Summarize and visualize the data
ETL
With Structured Data
Now, we analyze the phase of Data preparation. The first way is to use enterprise Data Warehouse, where the data is structured, and the data may come from sources such as the Online Transactional Processing (OLTP) applications and other sources such as Customer Relationship Management (CRM).
The core component of any data warehouse is a database, commonly use relational databases and SQL (Structured Query Language) to read and write data, use four basic operations that can be performed on a database: Create, Read, Update and Delete (CRUD).The common relational databases are Oracle Database, Microsoft Sql Server, IBM DB2 and PostgreSQL.
It’s ok, but what happens when you use unstructured data?
This is the second way; the tools and techniques change. We need remember the evolution of Databases to understand the new challenges in Big Data and how affected, in resume the “3 v´s ” (Velocity, Variety, Volume).
NoSQL (Not Only SQL)
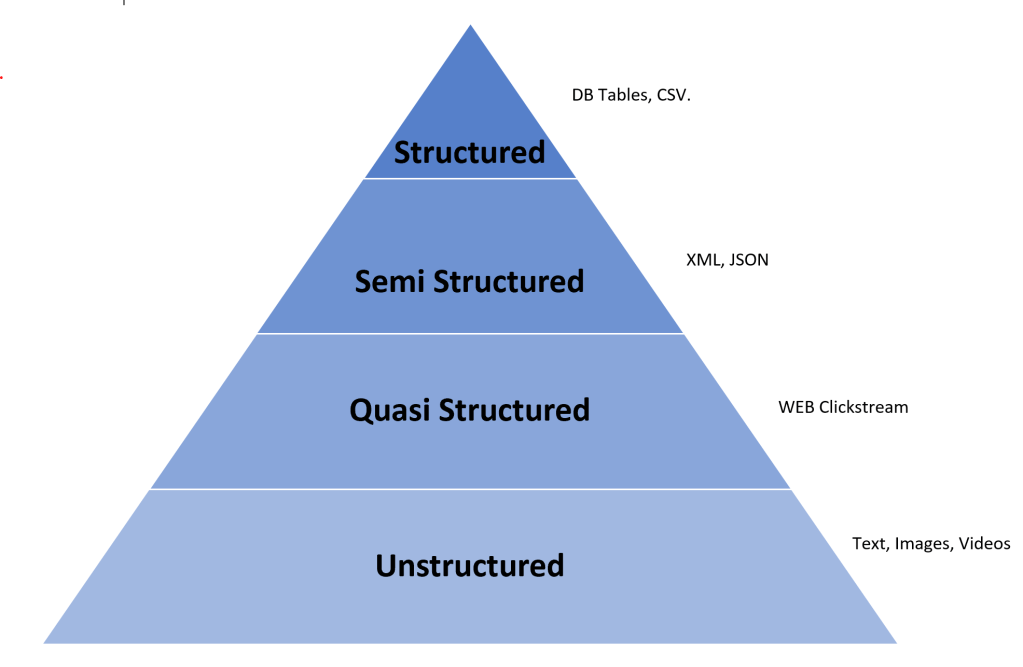
Refers to those tools and techniques that address data challenges not handled well by relational databases (structured data). The data can be unstructured (images, videos, audio, text) , semi- structured (XML, JSON) or quasi- structured (Web clickstream data).
In the Big Data ecosystem around the 80%-90% of the future data growth coming from unstructured, semi, quasi structured. This is the principal reason that we need to use appropriate tools for the ETL process.
Advantages NoSQL:
- Ideal for unstructured data and semi structured.
- High scalability
- Easy accommodates new data structures and data sources
- NRT reads and writes
The NoSQL Databases:
| Type | Tool |
| Key / value | Redis & Voldemart |
| Columnar | Cassandra & Hbase |
| Document | CouchDB & MongoDB |
| Graph | Flock & Neo4J |
It’s time to explain and understand the ETL process. So, how does the ETL process work?
Extract
This operation reads data from various source systems (Data Lakes, Data Island, Data Warehouse) and copies the required subset of data into the staging area.
Two types of data extractions:
- Full extraction: Extracting the data from source systems completely.This method is usually used when the data must be extracted and loaded into the staging area for the first time.
- Incremental extraction: Extracting and loading only the changes in the source data since the last extraction or after a complex business event.
Transform
This operation involves applying a set of rules on the extracted data to filter, clean and prepare the data into the desired format.
Common tasks are:
Filtering, cleaning, sorting, concatenating, splitting and deduplicating.
Load
This step involves loading the transformed data into the data warehouse or any target repositories.
- Full load: Entire data can be loaded into the data warehouse, which usually takes place when the data is loaded for the first time.
- Incremental load: Only the changed data can be loaded at regular intervals.
ETL steps can happen in parallel using pipeline concept. The crucial ETL steps are performed using programming tools that help in preparing the data for complex analysis. ETL Tools include: Apache Airflow and Bonobo. Thank you so much for read this post, I will write more to describe the different process and tools in Big Data ecosystem.

Written by Irving Ariel
EMC Education Services. (2015). Data Science and Big Data Analytics: Discovering, Analyzing, Visualizing and Presenting Data. Indianapolis: Jon Wiley & Sons, Inc.
